Get Started With CUDA Memory Management
· 5 min read

Data transfer between host and device
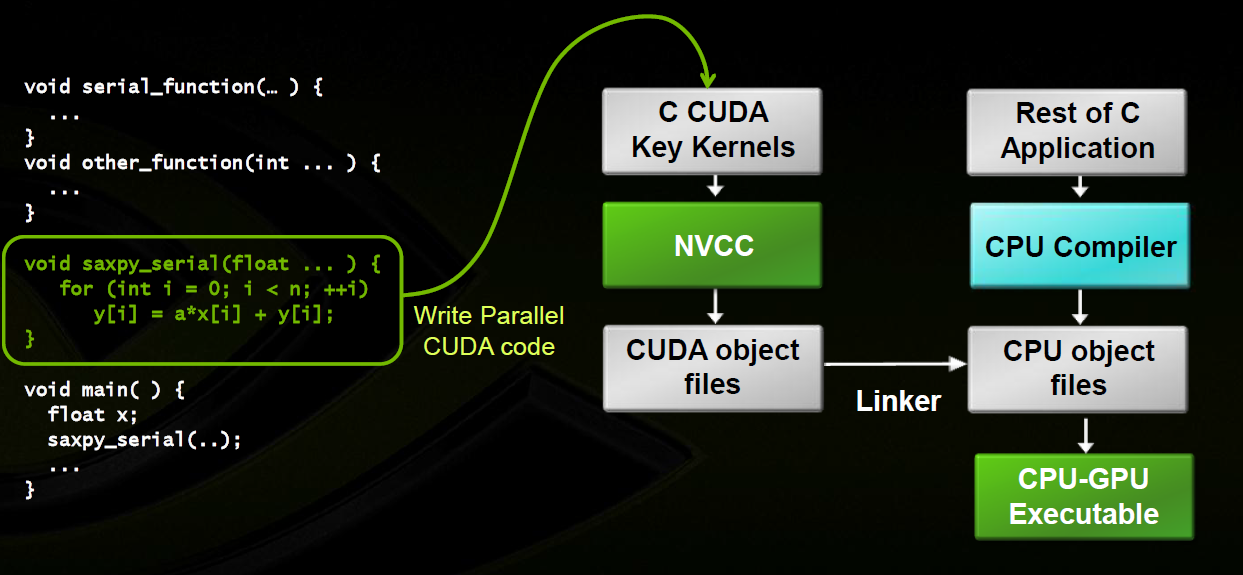
In CUDA programming, memory management functions are essential for optimizing data transfer between the host (CPU) and the device (GPU).
Copy from/to Pageable Memory
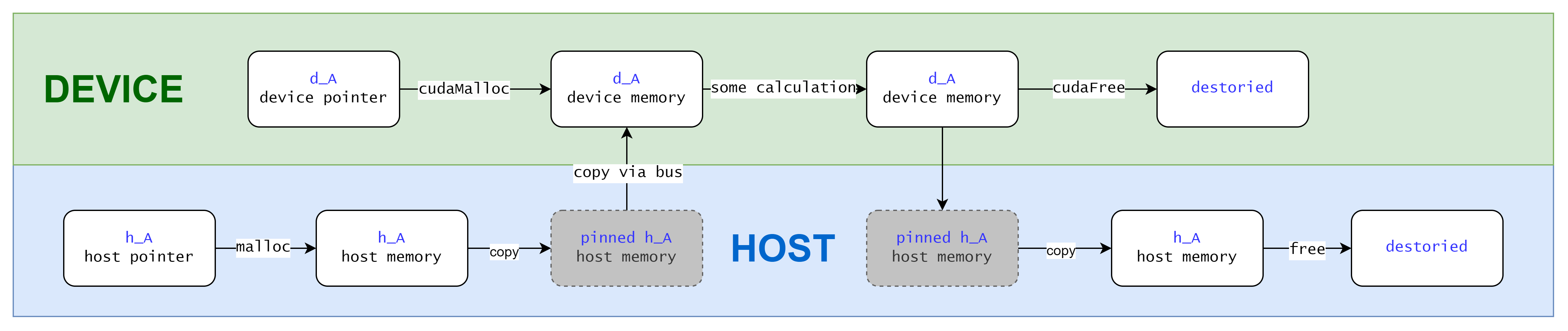
In this case you move data manually from host/device side to the other side.
You first malloc memory on host and copy it to device via cudaMemcpy. When the computation on device is finished, you copy the result back via cudaMemcpy again.
 Figure: Key components of a Fermi(a GPU architecture) SM
Figure: Key components of a Fermi(a GPU architecture) SM