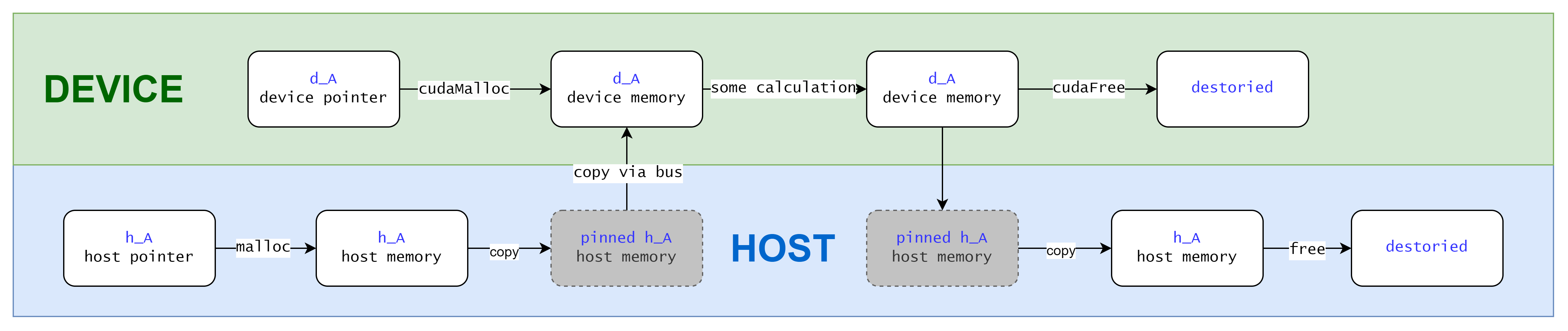
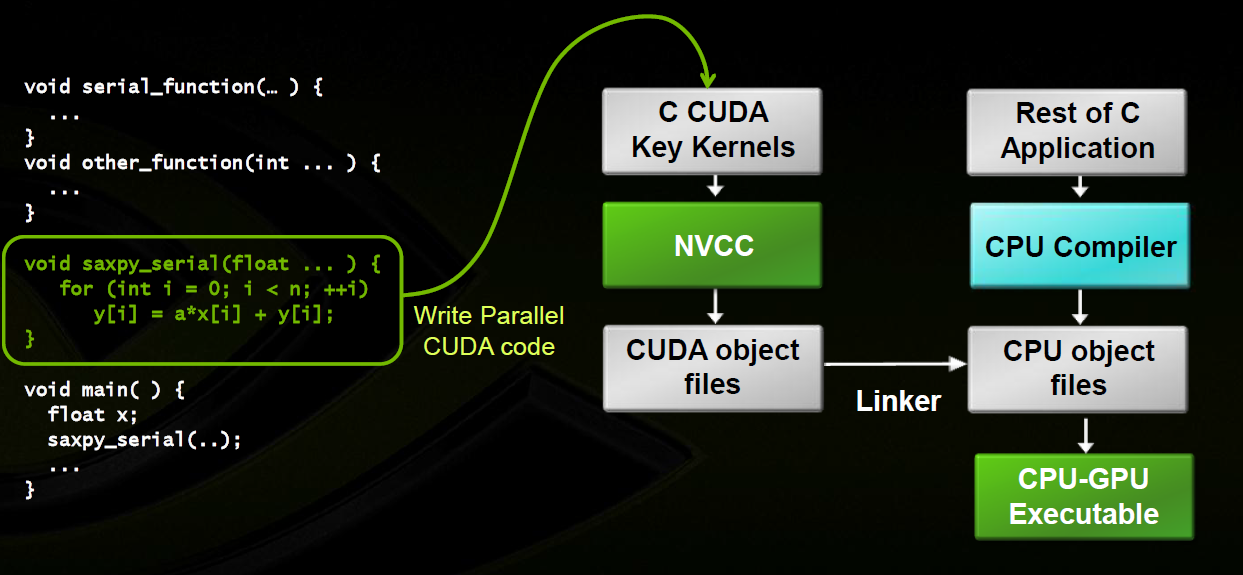
The starting point of all optimizations is to better "squeeze" hardware performance through programming.
The GPU architecture is built around a scalable array of Streaming Multiprocessors (SM). GPU hardware parallelism is achieved through the replication of this architectural building block.
Each SM in a GPU is designed to support concurrent execution of hundreds of threads, and there are generally multiple SMs per GPU, so it is possible to have thousands of threads executing concurrently on a single GPU. When a kernel grid is launched, the thread blocks of that kernel grid are distributed among available SMs for execution. Once scheduled on an SM, the threads of a thread block execute concurrently only on that assigned SM. Multiple thread blocks may be assigned to the same SM at once and are scheduled based on the availability of SM resources. Instructions within a single thread are pipelined to leverage instruction-level parallelism, in addition to the thread-level parallelism you are already familiar with in CUDA.
Key components of a Fermi SM are:
- CUDA Cores
- Shared Memory/L1 Cache
- Register File
- Load/Store Units
- Special Function Units
- Warp Scheduler
 Figure: Key components of a Fermi(a GPU architecture) SM
Figure: Key components of a Fermi(a GPU architecture) SM